Feature Store Function in Databricks — What You Need to Know

In 2021, Databricks launched an in-built feature storage & management layer in its workspace. This function can be accessed only through notebooks or workflows on Machine Learning runtimes. As you may know, a feature store is a centralized platform that contains all the curated features needed for Machine Learning model training and inference.
This blog gives a concise overview of the feature store function in Databricks. However, before we dive into the topic, let’s take a quick look at the history of feature store and what it is.
Evolution Of Feature Store
Feature store, as a novel concept, was first introduced by Uber in 2017. Since this invention significantly simplified the operationalization of Machine Learning objects, tech giants like Google and AWS increasingly started erecting venture-backed start-ups to launch feature stores as parts of their own platforms.
What Are Features?
A feature is a set of organized or transformed data that is required to train Machine Learning models and generate predictions. In other words, features contain the measurable input that is vital for ML modeling. Each feature contains feature values — measurable pieces of data like age, gender, amount, etc.
Features, also known as attributes or variables, are considered among the most critical elements for data science as they make the very inputs used during the machine learning process. They can be presented as columns in any given tabular data.
What is a Feature Store?
A feature store, as the name sufficiently depicts, is a storage site for essential inputs. It is a central repository that collects variables and readily makes them available for use. The stored information can be utilized either as datasets or data frames.
Feature stores act like data management layers and hence enable data scientists and other concerned personnel to use, develop, and share features. They work by transforming the raw data to make it usable for machine learning models, training, and inference.
The Link Between Features & Feature Engineering
Feature engineering involves the transformation of unrefined data into features. This transformation can be basic that includes mere aggregation or advanced processing like word embedding. The ultimate goal is to improve the quality of data to make it beneficial for machine learning algorithms.

Feature creation and engineering tend to eat up the largest amount of time of data scientists and Machine Learning engineers. That is why it is essential to keep a storehouse that keeps all of the previously designed features, so you do not have to recreate a new one every time a need arises. Just access the stored file, and you are good to go. Moreover, the quality of your features directly determines the performance and accuracy of machine learning models.
Significance of Feature Stores
It is essential to know the process of the ML lifecycle to appreciate the importance of feature stores. A Machine Learning lifecycle goes through the following four major phases:

Data scientists need features in both the modeling and production phases of ML system development. Machine Learning engineers also utilize the features but without a feature store. Keeping a feature store is beneficial because it handles the issue of duplication of code and provides consistency between inference and training of ML models.
Feature Store Function by Databricks
Databricks’ feature store is fully integrated and compatible with its other technology components. Let’s take a look at certain components and aspects of the feature store and how it makes it easier to manage features.
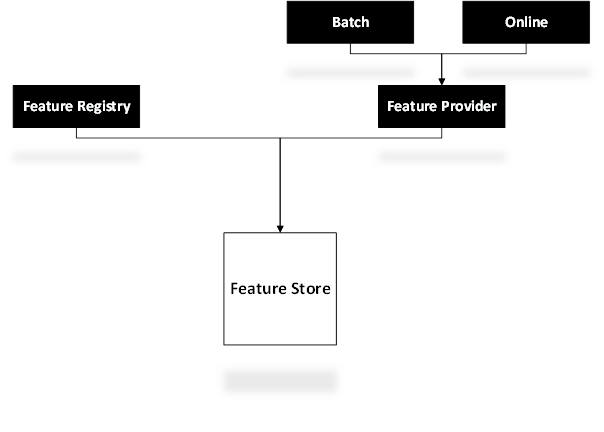
Feature Registry
Feature Registry keeps a record of all the curated features. It enables the users to look up and fetch the features whenever required and reuse them. By allowing this, the feature registry frees data scientists, ML engineers, and analysts from hours of needless work.
Feature Provider
As depicted by its name, a feature provider ensures the provision of features in two modes. While the batch mode is suitable for meeting high throughput feature needs, online mode provides features at lower throughput. The need can be for training Machine Learning models or utilizing features for BI purposes.
Feature Table
All features are presented as feature tables, and each table is supported by metadata that stores information regarding the relevant data source and jobs. In this way, it keeps track of how the table originated and from where. User can publish features on online stores to make them available for model inference in real-time. You can also categorize the tables with the help of tags to form a grouping.
Offline & Online Store
Offline store supports batch inference, feature discovery, and model training. In comparison, the online feature store is used for performing real-time ML model inference.
Streaming
You can also transform streaming data into features by adding values to the feature table from a streaming source. In addition, one can also transfer features between offline and online stores.
Training Set
A training set contains lists of features along with DataFrames. It can be formed by selecting features from the store. A Dataframe holds the training data as well as the labels and keys, which can be used to search for specific features.
Conclusion
Databricks feature store function is a storage layer where data science and ML engineering teams, working on Machine Learning models, can discover, store, and share features for model training and inference. It encourages integration, swift deployment, and increased discoverability of features.
Royal Cyber, a Consulting Partner of Databricks, has years of experience providing enterprises with tailor-made databricks solutions that promote efficient ML model building and hence improve analytics and strategic business decision-making. If you have any questions regarding this topic, feel free to contact our team.
Author bio:
Hassan Sherwani is the Head of Data Analytics and Data Science working at Royal Cyber. He holds a PhD in IT and data analytics and has acquired a decade worth experience in the IT industry, startups and Academia. Hassan is also obtaining hands-on experience in Machine (Deep) learning for energy, retail, banking, law, telecom, and automotive sectors as part of his professional development endeavors.
