Synapse Serverless SQL vs. Databricks Serverless SQL

Both Azure Synapse Serverless SQL and Databricks Serverless SQL afford the fusion of Data Lake and Data Warehouse. However, there are some key differences between the two regarding the relative cost, consistency, compatibility, and automatic governance they entail.
Data engineers and Data analysts can benefit greatly from computing through Synapse Serverless SQL and Databricks Serverless SQL but in different situations. All businesses require enterprise data warehousing that follows a relational data model to make most of the vast amount of data that is generated on a daily basis. Let’s compare the pros and cons of both Serverless SQLs to determine how they differ and identify what works best under specific circumstances.
Pros of Synapse Serverless SQL
Synapse Serverless SQL provides seamless storage and transformation facilities to its users. It does not require the setting up of special infrastructures, nor does it demand cluster maintenance. The followings are some of the major benefits of using Synapse Serverless SQL.
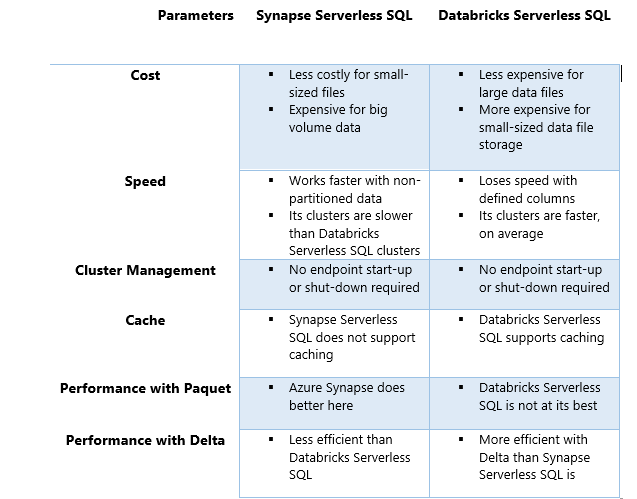
Synapse provides low-cost storage for small-sized data files
Synapse Serverless SQL provides effective storage for small-sized, non-partitioned data, i.e., up to 1 GB in size but is scattered across multiple sites and tables. The same cannot be said about Databricks SQL, though.
Synapse does better with Parquet than Databricks does
While handling a small amount of data, Azure Synapse Serverless SQL shows more efficient performance than Databricks SQL does with Parquet. It means that data storage and retrieval from Parquet file format is made easier with Synapse.
Azure Synapse does not demand endpoint restarts or shutdowns
Synapse serverless SQL makes itself readily available for query purposes. It does not require restarting and shutting down clusters at the start and the end of queries.
Synapse Serverless SQL works faster with non-partitioned data
When data is large but is not partitioned into multiple parts, Azure Synapse Serverless SQL provides remarkable speed to the runs. However, this speed comes to the fore only when Synapse is being run with Parquet and not Delta.
Provides consistency and stability
Since Azure Synapse serverless SQL does not endorse caches, it gives consistent and stable results throughout the processes happening within the data lake. It also provides maximum access to Application Programming Interface.
Azure Synapse Analytics — all-in-one
Azure Synapse Analytics is a service that brings data monitoring, management, and administration together to enrich the performance of Business Intelligence and Machine Learning departments. It acts as a data warehouse and a diagnostic tool at the same time. With the help of Azure Synapse Analytics can query data the way you like.
Cons of Azure Synapse Serverless SQL
There are also some downsides to the usage of Synapse Serverless SQL. They are mentioned below:
Synapse doesn’t carry cache; Databricks does
Synapse does not support caching. Caching stores information about the frequently accessed data. It uses such insights to make the experience enriched by making data readily available for the users.
High probability of a large number of timeouts due to the huge data size
If data quantity reaches one Terabyte, Synapse Serverless SQL may struggle to run with either Parquet or Delta. Databricks with Delta alone can finish the tasks reliably in such a case. Studies show that the frequency of downtimes increases substantially if the files are too many, especially if data is partitioned.
Synapse Serverless SQL clusters are slower than Databricks serverless SQL
Databricks clusters work faster on average than Azure Synapse Serverless SQL when large data files are involved. It gives Databricks Serverless SQL a natural edge over the latter.
Requires more manual management
A level of supervision is required to see through data formatting and structure specifications with Azure Synapse Serverless SQL. However, such sort of management is not needed while using Databricks.
Does not support Delta Optimally
Studies show that Synapse does not facilitate Delta-based data transmission and storage as optimally as Databricks does. Delta is a peculiar way of storing and transmitting data that works on the principle of difference.
Pros of Databricks
Databricks enhances the scalability and performance of data lakes by supporting features like automatic updates, instant compute, and whatnot. Read on to learn more about the pros of Databricks Serverless SQL.
Databricks Serverless SQL works better with Delta
While Databricks appears to run into timeouts sometimes while dealing with large-sized partitioned and non-partitioned data through Parquet, it gives an above-average performance when it comes to Delta.
Databricks is compatible with a large number of files and data types
Databricks Serverless SQL allows a lot of diversity. It runs smoothly for a variety of data types and file sizes. This feature makes it a very versatile platform that is proving itself to be an excellent asset for big data analytics and data engineering personnel.
Integrating BI with Serverless SQL is easy
Integrating Business Intelligence tools with Databricks Structured Query Language system requires minimum effort as there are in-built structures that provide immediate authentication. In this way, Databricks Serverless SQL facilitates the BI community by providing easy computing.
Instant compute with Databricks Serverless SQL
Instant computing is just another benefit of using Databricks Serverless SQL. It suits those who have tight schedules and need access to data all the time. With the help of Databricks Serverless SQL, analysts can do instant computing any time they want.
No over-provisioning with Databricks Serverless SQL
Over-provisioning, along with idle time, is significantly reduced by Databricks Serverless SQL. The system automatically stops clusters that stay inactive for ten minutes straight. It also withdraws the data resources to get ready for the next query in line. This automatic management of clusters makes a valuable property for analysts.
Cons of Databricks Serverless SQL
Just like the case is with Synapse, Databricks Serverless SQL also contains some not-so-desirable sides to it. They are listed below.
Performance with Parquet is not up to the mark
When compared with Synapse’s performance, it can be suggested that Databricks Serverless SQL lags behind Synapse Serverless SQL. However, it should be mentioned that Databricks does relatively fairly when it comes to Delta.
Databricks Serverless SQL loses speed with defined columns
When the columns and optimal types are clearly defined, Databricks Serverless SQL runs nearly three times slower than the Synapse Serverless SQL.
Expensive for a smaller load
Databricks Serverless SQL proves to be more expensive than Synapse Serverless SQL when the storage and processing of smaller load are involved.
Conclusion
Although Azure Synapse and Databricks Serverless SQL produce similar results in many situations, they are quite different in their performance under particular circumstances. For instance, while working with small data, a Data scientist may find Databricks Serverless SQL to be a more expensive than Synapse Serverless SQL. However, management of large data files and diverse data sizes is often less expensive with Databricks than it is with the Synapse Serverless SQL.
Author bio:
Hassan Sherwani is the Head of Data Analytics and Data Science working at Royal Cyber. He holds a PhD in IT and data analytics and has acquired a decade worth experience in the IT industry, startups and Academia. Hassan is also obtaining hands-on experience in Machine (Deep) learning for energy, retail, banking, law, telecom, and automotive sectors as part of his professional development endeavors.
